연구는 모집단에 some kind of 효과(effect)가 존재하는지 확인하는 과정이다.
ex> 효과(effect) : 우울증약을 투입한 모집단과 우울증약을 투입하지 않은 모집단에 차이가 있다(서로 다른 집단이다)
Statistical model : 통계모형
통계학의 가장 핵심이 되는 방정식 결과ᵢ = 모형 + 오차ᵢ
통계모형 : approximation of a real data
Fitting statistical model to data : 데이터를 가장 잘 대표하는/ 가장 적합한 모형을 선택하는 것/ 모수를 잘 예측할 수 있는 것(예 - 선형모형을 만들기 위해 표본데이터를 사용해서 slope, intercept을 정하는 것) model fit : how well does our model 'fit' the reality
Goodness-of-Fit(적합도 검정): an index of how well a model fits the data from which it was generated. it's usually based on how well predicted data(선형모형에서의 선(점 들)) correspond to the collected data(sample) ex) Chi-squared
선형모형(linear model) : 사회과학/행동과학자 대부분 선형모형을 쓰며, ANOVA/ regression 도 선형모형에 기초한 동일 체계 (하지만 비선형(곡선 등)이라도 선형으로 만드는 경향이 있기에, 연구시 그래프를 그려 비선형의 가능성을 보는 것도 좋다.
단순한 통계 모형 예시
평균 : 친구 평균 2.6명 처럼 가설상의(hypothetical) 값으로 통계 모형이라 할 수 있다. - 통계 핵심 방정식 : 결과ᵢ =평균+ 오차ᵢ ex) 강사1의 친구 수 = 강사들 평균 친구 수 + 오차
평균 적합(fit) 평가 : 제곱합(SS), 분산(s²), 표준편차(s) - SS, s², s : '평균' 통계모형의 적합도(평균(모델)이 자료를 얼마나 잘 대표하는지)측정 (s², s는 산포의 측도이기도 하다) -오차/변의성을 최소화 하는 모델이 가장 적합하다 - '평균' 모델에 대한 적합도 평가법 1. 편차를 구한다. *편차(deviation) : 통계모형이 평균일때 이탈도를 편차라고 이름 편차/이탈도(deviance) = 오차(error) = (실제자료값/관측값) - (모형 값(ex-평균)) = xᵢ - x̅ 2. 편차의 합을 구한다. 편차의 합은 0이므로, 오차제곱합(sum of squared error, SS)를 구한다. SS = Σ(xᵢ - x̅)² -SS: 자료가 모형으로부터 벗어난 정도 3. 관측값을 개수로 나눈다. SS는 자료수가 많을 수록 수가 커지므로, 오차가 커진다는 착각을 할 수 있다. 분산(s²) = SS/ N-1 - s² : 평균과 관측값 사이의 평균오차; 적합도의 measure 4. 제곱근 사용. 2번의 제곱 사용으로 직관적으로 수를 이해하기 어렵다. (예- 친구 (1.3명)² = 1.69명) 표준편차(s) = √(Σ(xᵢ - x̅)²)/N-1 - s : 평균이 얼마나 자료를 대표하는가
가설검정(hypothesis testing) : 통계적 모형을 이용하여 연구 질문을 검증한다.
검정통계량(test statistics)(≠ 효과의 크기)예) t, F, X². "반드시 확률로 이해하기" 검정통계량 =효과/ 오차 = (모형이 설명하는 변동, 체계적 변동) / (모형이 설명하지 못하는 변동, 비체계적 변동) - 검정통계량의 핵심은, 표본평균들 사이의 일반적 거리(변동, 표준오차)에 비해 조건의 차이가 더 큰지 아닌지를 확인하는 것이다. (떨어져 있는 정도가 일반적으로 표본들이 떨어져 있을 수 있는 거리면 그 차이는 유의미하지 않다.) N을 반영한 오차에 비해(분포의 모양으로 모평균을 얼마나 정확히 추정할 수 있는지를 결정), 두 샘플 평균의 거리가 월등히 더 크다면(5%만 가능한 확률로), 이건 오차가 아니라 어떤 효과때문일 수 있다는 추론을 하는 것이다(다른 모집단일 수 있다). - 여기서 표본분포/표준오차의 개념은 샘플 수(N)에 따라 그 형태와 크기가 달라지는 '이론적'인 것이므로 효과의 크기(N 무관)는 알아낼 수 없다. 단지, how certain 효과가 있을 수 있나를 확률적으로 알아낼 뿐이다. -참고: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3444174/ - 검정통계량의 분포를 알면, 특정 검정통계량 값을 얻었을 때 그 값이 나올 확률을 구할 수 있다 (분포표 사용) ex) t 분포 : df = 1일때, t = 127 (확률(alpha) = 0.0025), t = 6.3 (확률(alpha) = 0.05) - signifiance의 의미 : 효과가 우연히 발생할 확률보다 크다; not significant : 효과가 없는 것이 아닌, 효과가 있을 확률이 우연한 확률보다 적다.(≠ 효과의 크기) - 검정통계량의 한계 : 작은 효과거나 단순한 표본 간 차이라도 N이 크면 유의한 결과가 나올 수 있다
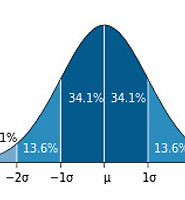
가설 검정의 오류 : 제 1종 오류(Type I error), 제 2종 오류(Type II error) * ⍺-level : 제 1종 오류가 생길 수 있는 확률 (.05, 5%) - 효과가 없는 모집단(H₀ distribution) 에서 추출한 100개의 표본 중 5개는 큰 검정통계량(효과가 있다고 믿을 정도)을 가짐 * β-level : 제 2종 오류의 허용가능한 최대치 (.2, 20%) - 효과가 있는 모집단(H₁ distribution)에서 100개 표본을 추출하면 20개는 효과가 존재하지 않는다는 결과를 얻게됨
One-tail vs Two-tail test(한쪽/양쪽 꼬리 검정): two-tail에서는 유의수준이 반으로 나뉘어, 유의하기가 더 어렵고, one-tail은 반대 효과를 놓칠 수 있다.
통계적 검정력(statistcial power, 1-β): 모집단에 효과가 존재한다는 가정하에 주어진 검정이 그 효과를 검출할 확률 - β가 .2 이므로, power의 기준은 .8, 즉 80% 확률로 검출할 수 있는 검정력을 목표 (임의의 효과를 검출할 수 있는 능력) - N, ⍺-level, power, N : 본질적으로 연결, 나머지 하나를 계산할 수 있다. 1. 검정력(1-β) 계산 : 실험 후, ⍺-level, N, effect size에 대해 알기에, 이를 기반으로 β-level을 계산할 수 있다. 2. 원하는 수준의 검정력에 필요한 표본크기(N) 계산 : ⍺-level, β-level, effect size(기존 실험으로 추정) -> N 계산 -> ex) ⍺ = .05, β = .80, effect size일 경우, (r = .1, 작은 효과를 검출하려면 783명; r =.3, 중간효과를 검출하려면 85명; r =.5, 큰 효과를 검출하려면 28명 필요)
효과크기(Effect size):표준화된효과의 크기(변수/척도가 다른 연구도 비교 가능);"확률이 아닌 실제 데이터의 값" -Cohen's 𝑑, Pearson's correlation coefficient 𝑟, odds ratio(승산비) - Pearon's R : intuitive with limits 0~1, but can be biased when group sizes are very discrepant(변동) r = .10 (small effect), r = .30(medium effect), r = .50(large effect) -> 각각 효과이 전체 변동의 1%, 9%, 25%임을 설명하나, 선형척도로 측정되지 않았기에, .1 -> .3이 효과의 세배는 아니다. 대략적 중요도를 알 수 있을 뿐, 문맥에서의 평가가 바람직함 - 메타 분석(meta-analysis) : 표본 하나로 모집단에서의 효과크기를 분석하기 어려움, 같은 질문의 연구 결과의 효과크기 결합출처 : Revista Comunicar
[복습]
모형이 어떻게 가설검증에 사용되는가? 1. 표본 추출 : 모집단있는 효과(ex-타이레놀이 효력이 있다)를 확인하기 위해, 모집단을 조사할 수 없으니 표본을 추출한다. 2. 모형 구축(fitting the model) : 표본데이터를 기반으로 통계모형(filling parameters like intercept/slope)을 만든다. - 모형을 통해 선형모델에서는 선의 모양(기울기 등)을, t-test 모델에서는 그룹내차이에 비한 그룹간 차이의 크기를 알 수 있다. 3. 가설 대입 : 통계 모형에서 효과보다 오차가 크다는 것은 (검정통계량(효과/오차)이 1이상으로 높다), 표본 데이터의 variability(변이성)가 오차보다는 효과로 설명될 수 있다는 것 (ex,선 45도) ->예, (그룹간 평균차이/그룹내 차이 = 4)라면, 이 것을 영가설 분포(표집분포관점)로 보면, 표준오차를 기준으로, 서로 평균차이가 그렇게 클 확률은 굉장히 적다 (5%미만). 그러므로 영가설은 기각된다. (서로 다른 모집단일 가능성이 높기에 -> 대립가설이 참이라 가정하는 서로 다른 모집단으로 계산해보면 높은 확률이 나온다.)